Adopter l’Intelligence Artificielle en entreprise : la vision Scopen

Comment adopter l’IA en entreprise sans compromettre ses valeurs ? L’approche Scopen pour une intelligence artificielle éthique et responsable.
Pourquoi accueillir l’IA (générative) en entreprise ?
L’adoption de l’Intelligence Artificielle en entreprise ne peut plus être traitée comme un simple effet de mode technologique. Les enjeux que nous avons explorés : impact environnemental, propriété intellectuelle, sécurité des données, démontrent qu’une approche réfléchie est indispensable pour éviter les écueils d’une intégration précipitée. Les entreprises qui se lancent dans l’IA sans stratégie claire risquent de compromettre leur sécurité informatique, de violer la confidentialité de leurs clients, ou de se retrouver dépendantes de solutions propriétaires coûteuses.

Cela dit, l’IA peut transformer concrètement le quotidien professionnel en automatisant et enrichissant de nombreuses tâches. En rédaction, on peut penser aux capacités d’amélioration de la forme des textes, à la correction des erreurs, ou bien sûr au temps gagné pour mettre au propre des notes. L’IA ouvre aussi aux petites équipes la possibilité de proposer de la personnalisation client. Par exemple, en adaptant des jeux de données, en personnalisant des campagnes marketing…
L’IA peut être un moteur de stimulation de la créativité en générant des idées de produits, proposant des angles d’approche inédits pour vos projets, ou suggérant des solutions innovantes à vos défis (à compléter bien entendu de toute l’intelligence humaine disponible !). Les outils de recherche avancée permettent d’analyser la littérature scientifique, la veille concurrentielle, ou les études de marché avec une profondeur et une rapidité qui ne cessent de s’améliorer. Enfin, la transcription automatique des réunions, autre exemple, était un outil très attendu. L’IA devient ainsi un véritable assistant (on a bien dit assistant) stratégique.
L’enjeu n’est plus de savoir si l’on doit adopter l’IA, mais comment l’adopter de manière stratégique et maîtrisée pour créer de la valeur réelle plutôt que de suivre simplement les tendances technologiques. En revanche, à ceux (gouvernement en tête) qui soutiennent la thèse d’un gain de productivité à toutes les échelles dès qu’une IA générative entre dans l’équation, le propos est peut-être à nuancer.
Définitions
Revenir aux bases, c’est important. Quand on parle d’adopter de l’IA dans son entreprise, on est vite submergé par tout un vocabulaire. Voici quelques points-clés qui peuvent vous intéresser :
Modèle
Un modèle d’IA est un ensemble d’algorithmes mathématiques capables de traiter et d’analyser des données pour produire des résultats. Contrairement à un logiciel traditionnel qui suit des instructions précises, un modèle « apprend » à partir d’exemples pour reconnaître des patterns et faire des prédictions. Les modèles « commerciaux » comme GPT, Claude, ou encore Mistral Medium sont les plus connus, mais il en existe des centaines, allant de très généralistes comme très spécialisés à certaines tâches.
Entraînement
L’entraînement est le processus d’apprentissage du modèle. Durant cette phase, le modèle analyse des milliers ou millions d’exemples pour comprendre les relations entre les données d’entrée et les résultats attendus. Plus les données d’entraînement sont variées et de qualité, plus le modèle sera performant dans ses tâches futures. Cette étape est cruciale car elle détermine la fiabilité et la précision du système final.
Biais algorithmiques
Les biais algorithmiques sont des distorsions systématiques dans les résultats d’un modèle d’IA, reflétant souvent les préjugés présents dans les données d’entraînement. Si votre modèle de recrutement est entraîné sur des données historiques favorisant certains profils, il reproduira ces discriminations. Ces biais peuvent avoir des conséquences juridiques et éthiques importantes, d’où l’importance de les identifier et de les corriger avant le déploiement.
Fine-tuning
Le fine-tuning consiste à spécialiser un modèle généraliste pour des tâches spécifiques. Plutôt que de créer un modèle de zéro (processus coûteux et complexe), vous prenez un modèle pré-entraîné et l’adaptez avec vos propres données métier.
Agents
Un agent d’IA est un système autonome capable d’agir dans un environnement pour atteindre des objectifs spécifiques. Contrairement à un modèle qui se contente de répondre à des questions, un agent peut prendre des décisions, planifier des actions et interagir avec d’autres systèmes. Le (très) rapide développement de ces agents vient questionner le monde du travail, avec la possibilité d’automatiser des métiers de plus en plus complexes, en répliquant des équipes entières.
C’est quoi l’IA open-source ?
L’Open Source Initiative (OSI) définit une intelligence artificielle open source comme un système mis à disposition selon des conditions garantissant aux utilisateurs les libertés suivantes :
Utilisation
Utiliser le système pour n’importe quelle finalité, sans nécessiter d’autorisation préalable.
Étude
Examiner le fonctionnement interne du système et comprendre comment ses résultats sont générés.
Modification
Adapter le système à d’autres fins, y compris en modifiant ses sorties.
Partage
Distribuer le système, avec ou sans modifications, à d’autres utilisateurs pour toute utilisation.
Pour qu’un modèle d’IA soit considéré comme open source, l’OSI précise que les éléments suivants doivent être accessibles :
Informations sur les données
Documentation détaillée sur l’origine, le traitement et les caractéristiques des données d’entraînement, y compris les méthodes de sélection, d’étiquetage et de filtrage.
Code source complet
Le code utilisé pour entraîner et exécuter le modèle, incluant le traitement des données, les tests et la validation.
Paramètres et poids du modèle
Les poids et autres paramètres appris, tels que les points de contrôle d’entraînement et l’état final de l’optimiseur, pour permettre la reproduction ou la personnalisation du modèle.
À l’heure actuelle, aucun modèle commercial n’a reçu ce sésame, le point de crispation résidant dans la base de données utilisée pour l’entraînement. Pour comparer certains modèles, le PEReN met à disposition un comparateur.
Pourquoi choisir son modèle et pourquoi ne pas utiliser un chat gratuit
Fuite de données
Les chatbots gratuits comme ChatGPT transforment vos conversations en données d’entraînement pour leurs futurs modèles. Chaque question posée, chaque document partagé, chaque problématique métier exposée enrichit les bases de données de ces entreprises. La gratuité apparente cache un coût invisible, la perte de confidentialité de vos informations sensibles. En hébergeant vous-même un modèle, vous gardez la maîtrise totale de vos données. Des acteurs européens comme OVHCloud vous proposent de le faire.
Impact environnemental
Utiliser un outil grand public signifie délocaliser vos calculs d’IA vers des datacenters souvent à l’étranger, et alimentés par des énergies fossiles. Les serveurs hébergés aux États-Unis ou en Asie, où l’électricité provient majoritairement du charbon et du gaz, amplifient l’empreinte carbone de chaque requête. À l’inverse, déployer un modèle localement ou sur des serveurs européens (ou mieux, Français 🇫🇷) alimentés par des énergies propres réduit significativement l’impact environnemental de votre usage de l’IA.
Pour en savoir plus, nous vous recommandons cet article de Carbone4 sur l’impact de l’IA sur le climat, ainsi que la lecture du bilan carbone fait par MistralAI.
Choisir son modèle, c'est choisir ses valeurs
Sélectionner consciemment son modèle d’IA revient à privilégier un modèle économique et éthique. Utiliser ChatGPT, c’est financer une entreprise américaine qui s’est approprié des millions d’œuvres sans autorisation, et dont les pratiques de collecte de données restent opaques. Chez Scopen, notre attachement au numérique éthique nous pousse à bannir ce genre d’outils.
Que fait Scopen ?
Chez nous, l’IA est un chantier stratégique que nous explorons depuis plusieurs mois. Nous nous documentons, expérimentons, et construisons petit à petit notre vision de l’intégration de l’IA dans nos processus. Nous souhaitons éviter l’approche de « l’innovation pour l’innovation » à tous prix, et utiliser des outils adaptés dans des processus précis et identifiés.
Par exemple, voici un résumé des contraintes que nous avons identifié lors d’un groupe de travail sur la question :
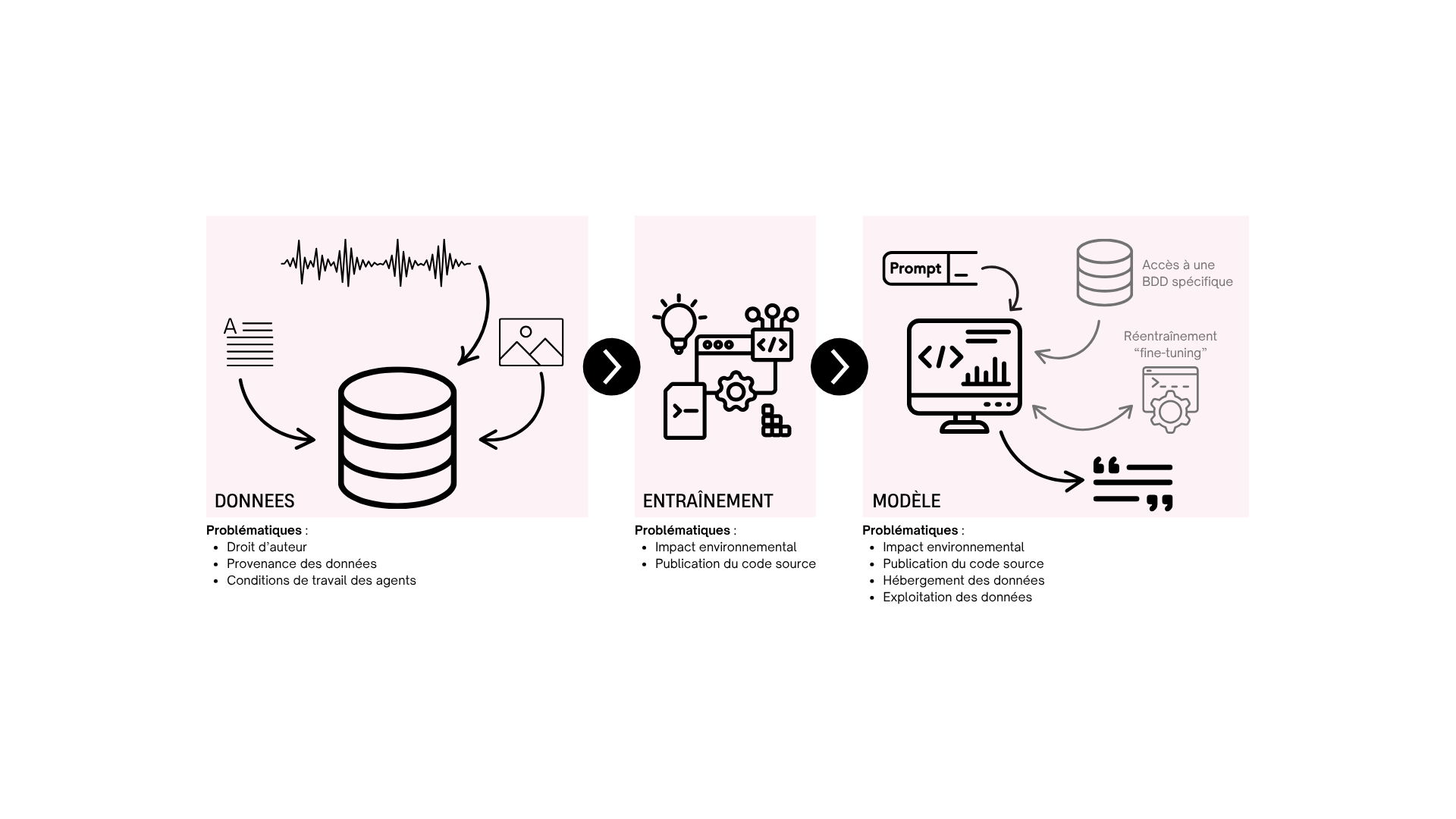
Nous avons délibérément exclu les solutions gratuites de notre réflexion, parfaitement conscients des risques de fuite de données qu’elles représentent pour nos clients et nous-mêmes. De fait, OpenAI, xAI, Google sont sur notre liste noire, au profit d’alternatives plus respectueuses (et pour autant pas moins performantes) comme Mistral AI. Comme pour le reste de nos outils, nous souhaitons soutenir une souveraineté numérique européenne, le respect de la vie privée de toutes et tous, et soutenir un écosystème technologique plus éthique et transparent. Nous sommes tout de même conscients du manque d’une solution réellement open source, que nous attendons avec impatience.
Notre utilisation de l’IA se veut raisonnée et ciblée : plutôt que d’automatiser à tout-va, nous identifions précisément les processus où l’IA nous apporte une réelle valeur ajoutée. Cette démarche s’accompagne d’une veille constante sur les innovations émergentes, nous permettant d’anticiper les outils qui pourraient demain simplifier de nouveaux aspects de notre activité.